
Cycle-Driven Engineering
Making AI-Assisted Engineering Work In Practice

Over the past 18 months I have been working on AI-assisted engineering across three very different settings. Inside a 5,000-engineer organisation, where I championed adoption across a number of teams. At Atherio, the company I am building, where I am CTO and sole engineer. And in two consulting engagements with mid-size engineering teams that were starting on the same path.
The settings had almost nothing in common on paper. Different scales, different stacks, different cultures, different ages of codebase. The constraints inside a 5,000-engineer organisation are nothing like the constraints of a one-person engineering team, or those of a mid-size team trying to scale.
What I did not expect, going in, was how much the problems would converge. The friction points looked different on the surface, but the underlying causes did not. And once I started addressing them, the solutions that worked were also the same. Or at least, they could be boiled down to the same handful of principles.
That repetition, across organisations that should have had nothing structural in common, is what made me think there was something more general going on than three separate stories.
Where AI Adoption Usually Starts and Why It Stalls
Most organisations introduce AI at the execution layer. They buy licenses. They roll out a coding agent across the engineering team. Very often, soon after, they put KPIs in place on AI usage. From the inside, it feels like the natural place to start.
The instinct usually rests on a flawed evaluation, though. In almost every organisation I have seen go through this, the first real evaluation of AI coding agents is done by a single engineer, working in isolation, on something that is not constrained by very much. A side project. A green-field service. A piece of internal tooling. That engineer reports productivity gains that look almost unbelievable, orders of magnitude faster than the same work would have taken without an agent. Decision-makers see the demo, see the numbers, and the conclusion seems to follow naturally: let us buy everyone a license.
What most teams realise within a few weeks is that the productivity gain reported by one engineer in isolation does not translate into the same gain at the level of the organisation. The team as a whole does not suddenly move orders of magnitude faster. In many cases it does not move much faster at all. Sometimes it moves more slowly, because the velocity of one part of the system has changed and the rest of the system is now visibly out of sync with it.
Accelerating execution inside systems built for slow feedback does not improve those systems. Instead, it just amplifies their inconsistencies. The friction that was already there is still there, but now it shows up faster, in larger volumes, and at a rate the rest of the organisation cannot absorb.
That observation is what eventually shifted the way I thought about the whole problem. For a long time I had been measuring AI adoption the way the organisations I worked with were measuring it: in productivity gains. The teams that were actually making progress, though, were not the ones chasing those gains. They were the ones building an engineering system that improved itself every cycle, where AI was one of several accelerators inside a system designed for fast feedback.
Once I made that shift, all the notes I took and lessons I learned throughout these 18 months began to fit together. Putting all those puzzle pieces together shaped what I now call Cycle-Driven Engineering.
Introducing Cycle-Driven Engineering
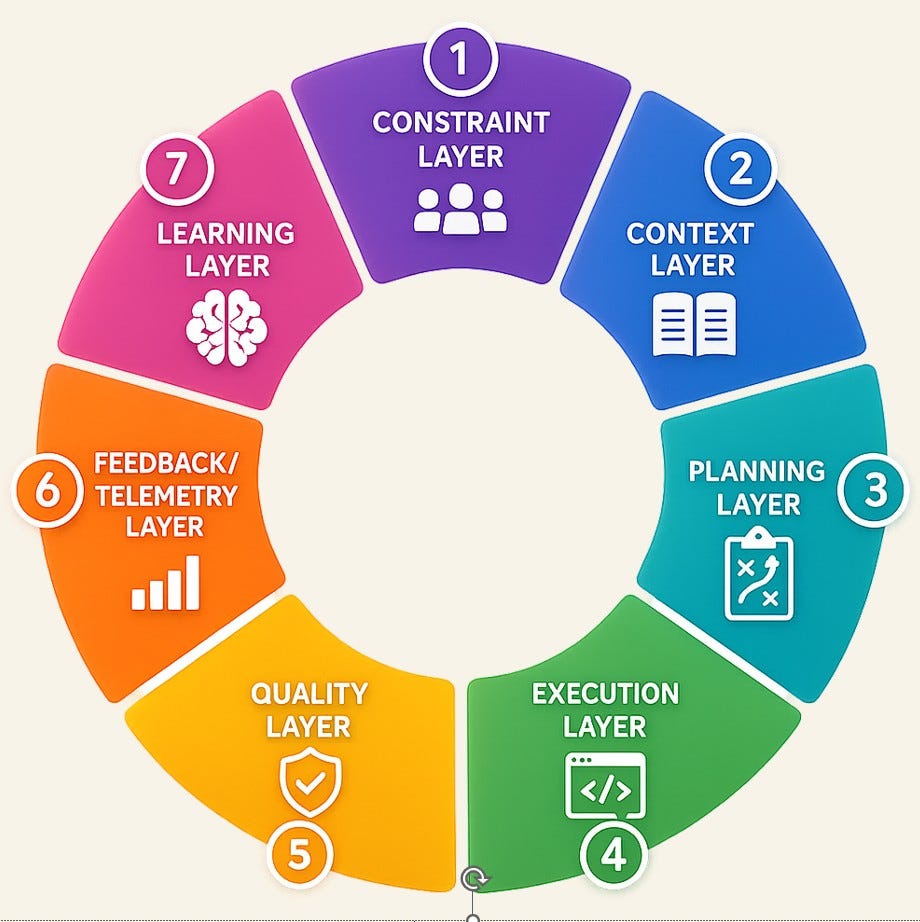
Cycle-Driven Engineering is built around what I call “The Engineering Loop”. Seven layers, each with a specific role: Constraint, Context, Planning, Execution, Quality, Feedback, and Learning. Every cycle of work passes through all seven in that order, and the output of the last layer feeds back into the first. That is what makes it a loop rather than a pipeline. The aim is for each pass through the loop to improve the conditions for the next pass. That is what compounding looks like at the level of an engineering organisation.
The order of the layers is not interchangeable. Each one removes a class of friction that the next one assumes has already been removed, which means a missing or weak layer forces the ones below it to carry that weakness forward. In practice, this usually shows up as the loop running, but not compounding.
The rest of this article walks through each of the seven layers at altitude. Each will get its own deep dive in the weeks that follow.
1. The Constraint Layer
The Constraint Layer is the first layer in the loop, and it sits there for a reason. It is the layer that defines who gets to decide what, on what timeline, and inside which boundaries. Every other layer in the operating model assumes that those questions have a clear answer. When they do not, the friction propagates downward into context, planning, execution, and the rest of the loop, and no amount of work in those layers compensates for it.
This layer is also different in nature from the ones that follow. Most of the work here is organisational rather than technical. It is leadership work, and it usually requires reshaping parts of the organisation’s operating model: how decision rights are distributed, how approval flows are structured, how teams are designed, and how knowledge is shared across them. Engineering leaders cannot fix this layer alone. It has to be addressed at the level of the organisation that engineering sits inside.
The Constraint Layer covers clear decision ownership and decision SLAs, the elimination of approval chains that block execution, and making decisions explicit and documented rather than implicit in conversations. It also covers a single source of truth for shared knowledge, stable architectural boundaries that reduce cross-team dependencies, and team design that supports independent execution rather than coordination-heavy work.
2. The Context Layer
The Context Layer sits second in the loop because everything that follows depends on it. Planning cannot produce concrete steps against a system whose architecture is implicit. Execution cannot stay aligned with a system that has no documented patterns. Quality cannot enforce standards that have not been written down. The Context Layer is what turns a system from something that lives in people’s heads into something that humans and AI agents can both reason against.
Unlike the Constraint Layer, the work here is largely a technical and engineering responsibility, but it has a discipline component that most teams underestimate. Documentation has to stay current as the system evolves, which means it cannot be treated as a separate stream of work that happens after the fact. It has to be part of the workflow itself.
The Context Layer covers a single, structured documentation source for the system, with architecture documented explicitly rather than left as tribal knowledge. It uses machine-readable formats such as diagrams and structured markdown. Coding standards and conventions are encoded in repo-level files, and clear patterns and examples are provided for common implementations. Context is kept accessible to both humans and AI agents, with documentation maintained as part of the workflow rather than alongside it. Documentation is treated as a system dependency, not as optional support, and a documentation index feeds into agent skills and rules.
3. The Planning Layer
The Planning Layer is where the work for a given cycle gets defined before any code is written. It sits between context and execution because it is the layer that translates a stable system, with known constraints and documented architecture, into a concrete plan that execution can follow without having to invent anything along the way. If the layers above it are solid, this is where most of the cycle’s thinking actually happens.
The discipline this layer requires is one of the harder shifts for teams adopting AI-assisted engineering. The traditional view is that planning stays high-level and detail belongs to execution. That worked when execution was slow enough to absorb ambiguity, but it does not hold when execution is fast and fluent. Every gap left in the plan becomes a small architectural decision made in the moment by an agent that has no opinion on the system’s future. Planning has to descend to a level of detail that previous workflows did not require.
The Planning Layer covers explicit implementation plans defined before execution starts, with work broken into small, deterministic steps of about an hour or less. Architecture decisions are captured upfront in ADRs. Every step has clear acceptance criteria, and sample code implementations are included in the plan where they help remove ambiguity. Plans are aligned with the existing context and system constraints, and ambiguity is eliminated before execution begins. Planning is treated as a mandatory phase, not as optional refinement.
4. The Execution Layer
The Execution Layer is where the code is actually produced. It is the most visible part of the loop, and it is the part most teams focus on first when they start using AI coding agents. In Cycle-Driven Engineering, this layer is deliberately the smallest and most constrained. By the time work reaches it, the architectural decisions have already been made in planning, the context that informs them is already documented, and the boundaries within which the work happens are already settled by the constraint layer above. There is very little left for execution to figure out, which is the point.
This is also the layer where the role of AI is the most direct, but also the most narrow. AI generates. Humans guide and review. The agent’s job is to produce code against a clear plan, not to make decisions about the system. When the layers above are doing their job, this works well. When they are not, execution becomes the place where every weakness in the system above it shows up in the codebase.
The Execution Layer covers strict adherence to the defined plan, with no improvisation. AI is used to generate, not to decide. Humans stay in the loop for guidance and review. Execution scope is kept to small, well-defined steps, and every change is traceable to a step in the plan. On-the-fly decision making is avoided during execution. Iteration happens in fast, controlled cycles, and execution is treated as deterministic rather than exploratory.
5. The Quality Layer
The Quality Layer is where the standards of the system are enforced automatically, rather than relying on individual reviewers to hold the line. It sits after execution, but in practice it works in a tight loop with it. The job of this layer is to evaluate what execution produced against the system’s expectations, and when the work falls short, the result is not a review comment for a human to act on later. It feeds directly back into execution, and the agent continues working until the quality gates are met. Execution and quality together form a small inner loop inside the larger Engineering Loop, and a cycle of work only leaves these two layers when every gate has passed.
This is also the layer that most clearly cannot be optional in an AI-assisted setup. The volume and pace of code being produced are too high for manual review to function as a real gate, and without enforced standards the system accumulates small inconsistencies far faster than humans can catch them. The shift this layer requires from most teams is to stop treating quality as a review activity that happens at the end, and start treating it as a property the system enforces continuously, in tight coordination with execution itself.
6. The Feedback Layer
The Feedback Layer is where the system makes its own behaviour visible, both to humans and to agents. It sits after execution and quality because the work has by then been merged and is running in real conditions, and the loop now needs a way to understand what is actually happening as a result of that work. Without this layer, the cycle ends at the moment of release, and everything that follows in production is invisible until something breaks badly enough to surface on its own.
The role of this layer is broader than incident response. It is the layer that produces the raw material for reasoning about the system: what the system is doing, how it is behaving under real load, where it is slow, where it is failing, where it is degrading quietly. That raw material is what makes the next layer possible, because there is nothing to learn from if there is nothing observed in the first place.
The Feedback Layer covers structured logs, metrics, and traces instrumented across the system, with OpenTelemetry as the standard. All activity is correlated through end-to-end trace IDs that follow a request across jobs, databases, and external calls. SLIs and SLOs are defined and monitored for latency, errors, and throughput.
7. The Learning Layer
The Learning Layer is the layer that turns The Engineering Loop into an actual loop rather than a sequential pipeline that runs the same way on every cycle. It sits at the end because it is the layer that takes everything the cycle just produced, the decisions made, the plans executed, the quality outcomes, the feedback observed, and feeds it back into the layers that started the cycle in the first place. Without this layer, the loop runs, but it does not improve.
The shift this layer requires is in what is being evaluated at the end of a cycle. Most engineering organisations evaluate the output: whether the feature shipped, whether the bug was fixed, whether the deadline was met. The Learning Layer asks a different question of every cycle, which is whether the conditions for the next cycle are now better than they were for this one. That is what makes the loop compound. It is also what makes Cycle-Driven Engineering a model for the engineering organisation as a system, rather than a collection of practices applied to individual cycles.
The Learning Layer covers feeding iteration learnings back into context, planning, and constraints. Documentation, patterns, and system rules are continuously updated based on real behaviour observed through the previous layers. Failures, edge cases, and deviations are turned into system-level improvements rather than handled as one-off fixes. Every cycle is expected to leave the next cycle’s execution environment in a better state than it inherited. Workflows are designed to expose trade-offs and system behaviour, so the team can see clearly where the system is working and where it is not. Engineers’ judgment is built deliberately, by requiring them to define constraints and expected outcomes, and evaluation shifts from output to decision quality and the reasoning behind it.
Closing Thoughts
Cycle-Driven Engineering and The Engineering Loop is what came out of 18 months of trying to make AI-assisted engineering work in organisations that had very little in common on the surface. The seven layers are not a complete description of every practice that matters, and they are not meant to be. They are the set of structural conditions that, when they are all in place, allow an engineering organisation to actually compound its work cycle after cycle, rather than just running faster.
Each of the seven layers will get its own deep dive in the weeks that follow, with the configurations, the workflows, the places where this has worked and the places where it has broken. By the end of the series, the loop should be concrete enough to argue with.
The thing I want to leave with at the end of this introduction is the observation the model is built around. AI on its own is not really the answer to engineering productivity. It is an accelerator, and most engineering systems were not designed to be accelerated. The work, before tooling, is on the system.
I would be curious to hear how this lands against your own experience of AI adoption. If parts of Cycle-Driven Engineering match what you are seeing, or if your reality looks different, the comments are open. If the article was useful to you, sharing it with someone going through the same kind of work helps more than it sounds like it should.